
2026年4月10日发布 | 本文约6200字,阅读需12分钟
AI浪潮席卷办公软件赛道,企业微信已成为这场变革的前沿阵地。从智能机器人一键创建,到开源CLI让AI Agent直连企微核心能力,再到多智能体协同完成复杂工作流——根Ai企微助手正以极低的技术门槛,推动企业级AI助手从“概念”走向“日常”。许多开发者面临着同样的困境:会用但不懂原理、概念容易混淆、面试答不出底层逻辑。本文将带你从痛点出发,深入理解Agent与RAG的核心概念、剖析两者协同关系,通过代码示例还原技术链路,并梳理高频面试考点,建立完整知识链路。
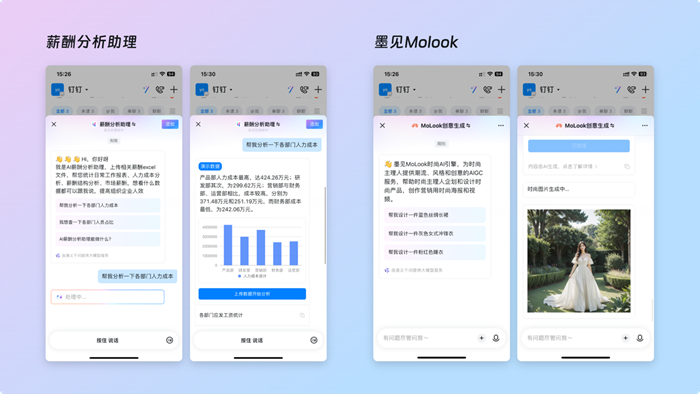
一、痛点切入:为什么企业需要根Ai企微助手?
传统企业办公的“三大痛点”
在没有AI助手加持的企业微信场景中,痛点十分突出:
痛点一:知识查找效率低下。 员工需要从海量聊天记录、文档、邮件中手动查找资料,一个简单的“报销流程是什么”可能耗时数分钟甚至更久-1。
痛点二:重复性工作占用大量人力。 IT支持、行政答疑、客户咨询等高频重复问题,消耗了大量员工的宝贵时间。以客服场景为例,传统模式下客服响应时间平均长达8分钟-4。
痛点三:跨系统操作割裂。 一项工作任务往往需要在多个模块间来回切换:查通讯录→建会议→发消息→写文档→同步待办,每一步都依赖人工操作,流程冗长且易出错-3。
根Ai企微助手的解决方案
根Ai企微助手的出现,正是为了解决上述痛点。它通过以下机制实现智能化升级:
自然语言理解与知识检索:将企业内部知识集(产品资料、规章制度等)上传后,智能机器人会对用户问题进行资料匹配,结合大模型进行推理,给出精准回答-1。
自动化任务执行:通过CLI接口,AI Agent可以直接调用消息、日程、文档、会议、待办、通讯录、智能表格等7大类核心办公能力,将多步骤流程串联执行-3。
7×24小时在线响应:覆盖IT支持、行政答疑、资料检索、报销规则查询等场景,秒级响应需求-1。
二、核心概念讲解:AI Agent(智能体)
2.1 什么是AI Agent?
AI Agent(人工智能智能体) 是指能够感知环境、进行自主决策并执行行动以完成特定目标的智能实体。简单来说,它不仅是“回答问题”的对话模型,更是“完成任务”的自主执行者。
2.2 拆解核心关键词
“自主规划” :Agent能够将复杂任务分解为可执行的子任务序列。例如,用户说“安排一场周一下午三点的项目会议”,Agent需要自动分解为:查参会人闲忙→预约会议室→创建会议→发送邀请→创建待办。
“工具调用” :Agent具备调用外部工具的能力,通过Function Calling机制与外部API交互,扩展其能力边界-60。
“感知-规划-行动”闭环:Agent的工作流程包含三个核心环节——感知环境变化→规划行动路径→执行具体操作,并持续反馈优化。
2.3 生活化类比
可以把AI Agent想象成一个“能干的私人助理” :你只需要说出目标(“帮我整理下周的客户跟进情况”),助理会自行拆解任务(查聊天记录→整理重点→生成报告→发邮件),并调用各种工具(日历、文档、邮件系统)来完成,你只需验收最终结果。
三、关联概念讲解:RAG(检索增强生成)
3.1 什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将大语言模型与外部知识检索相结合的技术架构,旨在解决大模型的知识滞后和幻觉问题-30。
3.2 核心原理
RAG的核心是一个“先检索、后生成”的四阶段流程:
索引阶段(Indexing) :将企业内部知识文档进行分块处理,提取向量特征,存入向量数据库-30。
检索阶段(Retrieval) :当用户提问时,将问题向量化,在数据库中检索最相关的内容片段。
融合阶段(Fusion) :将检索到的上下文与原始问题融合,形成增强后的提示词。
生成阶段(Generation) :大模型基于增强提示词生成精准答案。
3.3 生活化类比
RAG就像给大模型配了一个“随身图书馆” 。平时的大模型依靠训练时记住的知识回答(可能过时或不准确),而RAG允许它在回答前先去翻阅最新资料。这好比考试时,你是靠记忆力闭卷答题,还是允许翻书开卷答题——后者显然更准确、更可靠。
四、Agent vs RAG:概念关系与区别总结
4.1 逻辑关系:思想 vs 工具
Agent是“大脑” :负责目标理解、任务拆解、行动规划、工具调度。
RAG是“记忆库” :负责知识检索、信息增强、证据支撑。
两者的关系可以概括为:Agent是决策中枢,RAG是知识引擎。Agent决定“需要查什么资料、为什么查”,RAG负责“从哪查、怎么查、返回什么”。
4.2 区别对比
| 维度 | AI Agent | RAG |
|---|---|---|
| 核心功能 | 自主决策 + 执行任务 | 知识检索 + 增强生成 |
| 交互方式 | 多轮任务推进 | 单轮检索-生成 |
| 是否调用工具 | 是(可调用API、CLI等) | 否(仅检索知识库) |
| 能力边界 | 任务规划、多步执行 | 精准问答、证据生成 |
| 典型场景 | 工作流自动化、跨系统操作 | 知识库问答、文档摘要 |
4.3 一句话记忆
Agent是帮你“做事”的,RAG是帮你“找答案”的。
在根Ai企微助手中,两者往往协同工作:Agent负责规划任务流程,当需要查找知识时调用RAG检索内部资料,然后将检索结果用于后续行动(如撰写回复、生成报告)。
五、代码示例:根Ai企微助手的核心实现
5.1 接收消息与智能回复
企业微信智能机器人的核心交互流程如下:用户发送消息后,企业微信后台向开发者回调URL推送加密消息,开发者服务接收并处理后返回回复-11。
极简代码示例(Python + Flask):
import requests import json from flask import Flask, request app = Flask(__name__) 企业微信消息回调接口 @app.route('/wecom/callback', methods=['POST']) def handle_wecom_message(): 1. 解密接收到的消息(企业微信采用AES加密) req_data = request.get_json() msg_type = req_data.get('msgtype') from_user = req_data.get('from', {}).get('userid') if msg_type == 'text': user_input = req_data['text']['content'] 2. 调用大模型 + RAG检索 answer = process_with_rag(user_input) 3. 返回流式回复 return { 'msgtype': 'stream', 'stream': {'content': answer, 'finish': True} } return {'msgtype': 'text', 'text': {'content': '收到消息,正在处理...'}} def process_with_rag(question: str) -> str: """RAG检索 + 大模型生成""" Step 1: 向量化检索相关文档 relevant_docs = vector_db.search(question, top_k=5) Step 2: 构建增强提示词 context = '\n'.join([doc['content'] for doc in relevant_docs]) prompt = f"基于以下资料回答问题:\n{context}\n\n问题:{question}" Step 3: 调用大模型生成回答 return llm.generate(prompt)
5.2 CLI模式:让Agent直接操控企业微信
2026年3月,企业微信正式开源了CLI工具,AI Agent可通过命令行直接调用企微的核心办公能力-3。
1. 安装企微CLI npm install -g @wecom/cli 2. 初始化配置(交互式写入机器人凭证) wecom-cli init 3. 调用通讯录查询成员 wecom-cli contact get_userlist '{}' 4. 创建待办事项 wecom-cli todo create '{"title":"整理客户需求","due":"2026-04-15"}' 5. 发送群消息 wecom-cli msg send_text '{"chatid":"GROUP_ID","content":"项目进度更新"}'
执行流程解析:Agent接收用户指令(如“把待办同步到群里”)→解析意图→生成CLI命令→执行命令→企微API执行操作→返回执行结果。整个过程无需模拟点击或解析复杂API,Agent用“母语”(纯文本命令)直接操控企微-6。
六、底层原理与技术支撑
6.1 大模型推理引擎
根Ai企微助手背后依赖大模型推理引擎完成语义理解与生成。目前主流引擎包括vLLM(PagedAttention实现高吞吐)、SGLang(RadixAttention支持复杂推理)和TensorRT-LLM(NVIDIA极致优化)-48。
底层机制:vLLM通过分页式KV缓存管理,将显存利用率提升至90%以上,实现连续批处理和动态调度,从而支撑企业级高并发场景-48。
6.2 消息回调与长连接技术
企业微信支持两种API模式接收消息回调:
| 模式 | 连接方式 | 适用场景 |
|---|---|---|
| Webhook(短连接) | 每次回调建立新连接 | 普通回调场景,服务端有公网IP |
| WebSocket(长连接) | 复用已建立连接 | 内网部署、高实时性要求 |
长连接模式下,开发者无需处理消息加解密逻辑,通过SDK建立持久化连接,实时接收用户消息推送-13。
6.3 RAG的核心支撑技术
RAG的实现依赖三大技术基石:
Embedding模型:将文本转换为高维向量,用于语义相似度计算
向量数据库:存储和检索向量,如FAISS、Milvus、Chroma
分块策略:将长文档切分为语义完整的文本块,兼顾检索效率与信息完整性
七、高频面试题与参考答案
面试题1:Agent和RAG有什么区别和联系?
参考答案:
区别:Agent是自主决策与执行的智能实体,核心能力是任务规划和工具调用;RAG是检索增强生成技术,核心是知识检索与证据生成。
联系:两者可协同工作,常见结合模式包括(1)RAG作为Agent的工具,由Agent按需调用;(2)Agent增强RAG,由Agent动态优化检索策略;(3)混合架构,两者并行工作-62。
一句话记忆:Agent是“大脑”负责规划和执行,RAG是“记忆库”负责提供知识。
面试题2:RAG为什么能解决大模型的幻觉问题?
参考答案:
大模型依赖训练时记忆的参数化知识,存在知识滞后、事实性错误等问题,即“幻觉”-30。
RAG通过引入外部知识检索,将生成过程与可验证的实时证据耦合,让模型在生成前先获取相关资料。
四阶段流程(索引→检索→融合→生成)确保回答有据可查,显著降低幻觉风险。
面试题3:企业微信智能机器人的消息接收有哪些技术方案?各自的适用场景是什么?
参考答案:
Webhook(短连接) :每次回调建立新连接,需要公网可访问的URL,适合普通回调场景,复杂度低-13。
WebSocket(长连接) :复用已建立的长连接,无需固定公网IP,适合内网部署和高实时性场景,需维护心跳保活。
选择建议:服务端有公网IP且对延迟不敏感选Webhook;内网部署或追求低延迟选WebSocket。
面试题4:什么是Function Calling?在Agent开发中起什么作用?
参考答案:
Function Calling是大模型调用外部工具或API的能力,模型可输出结构化的函数调用指令-60。
在Agent开发中,它是连接“大脑”和“手脚”的关键桥梁——Agent通过Function Calling调用天气API、数据库查询、CLI命令等外部能力。
在根Ai企微助手中,Agent通过CLI命令调用企微核心功能,正是Function Calling机制的具体落地。
面试题5:大模型的核心能力有哪些?
参考答案:
自然语言理解:读懂用户意图和上下文-60
自然语言生成:生成流畅、连贯的文本
逻辑推理:数学推理、多步思考
多轮对话:维护上下文状态
内容创作:文案、代码、摘要等
工具使用:通过Function Calling扩展能力边界-60
八、结尾总结
核心知识点回顾
| 层级 | 知识点 | 一句话概括 |
|---|---|---|
| 痛点 | 传统办公的三大痛点 | 知识查找慢、重复劳动多、跨系统操作割裂 |
| 概念A | AI Agent(智能体) | 自主决策、任务规划、调用工具的“大脑” |
| 概念B | RAG(检索增强生成) | 先检索外部知识、再生成的“记忆库” |
| 关系 | Agent vs RAG | 决策中枢 vs 知识引擎,常协同工作 |
| 技术 | 企微消息回调 | Webhook短连接 / WebSocket长连接 |
| 底层 | 推理引擎 + 向量检索 | vLLM分页内存管理、Embedding向量化 |
| 面试 | 5道高频题 | 概念辨析、技术选型、原理阐述 |
重点与易错点强调
切忌混淆Agent与RAG:Agent强调“做”,RAG强调“找”,两者定位不同但可协同。
企微消息回调务必注意加密:企业微信采用AES加密传输,开发时需正确实现加解密逻辑-11。
长连接模式需维护心跳保活:建议间隔30秒发送心跳,避免连接被服务端主动断开-13。
下一篇预告
本文以“根Ai企微助手”为主线,围绕Agent、RAG和企微技术栈进行了系统讲解。下一篇将深入多智能体协作架构——当Agent不止一个时,如何设计指挥官(Orchestrator)实现任务分解、智能调度与结果融合-20。从单兵作战到军团协同,敬请期待!
📌 学习建议:建议读者按照“理解痛点→掌握概念→编写示例→复习考点”的顺序阅读本文。强烈建议亲自动手,在企业微信后台创建一个测试智能机器人,尝试完成消息接收与回复的完整流程。实践出真知,动手写一遍比读十遍更有效!
 扫一扫微信交流
扫一扫微信交流